Informer Rest API
API Basics
Informer Base URL
https://xxxbi.navigahub.com/api/
Endpoint or Route
xxxbi.navigahub.com/api/datasets/OWNER:datasetname/data
Query Parameters
xxxbi.navigahub.com/api/datasets/OWNER:datasetname/data**?start=0&limit=50**
You will find that the endpoinfall into two basic categories, either Datasets or Ad Hoc Query Reports.
The main difference is that when you request data from an Ad Hoc Query report, it must execute the query against the Naviga database and then return the data. The Dataset data is cached, so when you request data from it, you will be getting the last refreshed data. This makes datasets the most performant of the two options.
Informer has Swagger documentation on the Rest API available at <your server name>/documentation
Authenticating
All REST requests are authenticated and authorized by the Informer server. Informer supports three authentication methods as outlined below:
- Session – Uses a session cookie that is set after a successful login and carried with each REST request
- Token – This is a query parameter attached to a request URL that allows the route access to the resource. A token is created within Informer for each Dataset or Report that is being accessed via the REST API.
- Basic – HTTP Basic authentication method where username and password are passed using the HTTP Authentication Header.
Session Login
Session login can be useful if you are building an web application. You can have it set a cookie with an authentication token.
To login, you will use the following POST route:
/api/login/local
The body of the post will be a JSON object:
{
"username": "username",
"password": "123password"
}
Token Authentication
From the Dataset or Report Action menu, choose to Create a data access token.
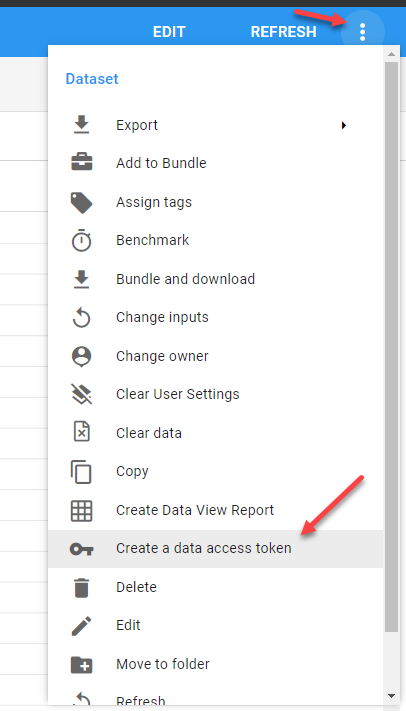
The Edit Token dialog will give you some options, but you will just want the "Token Only" option if you are building your own API calls.
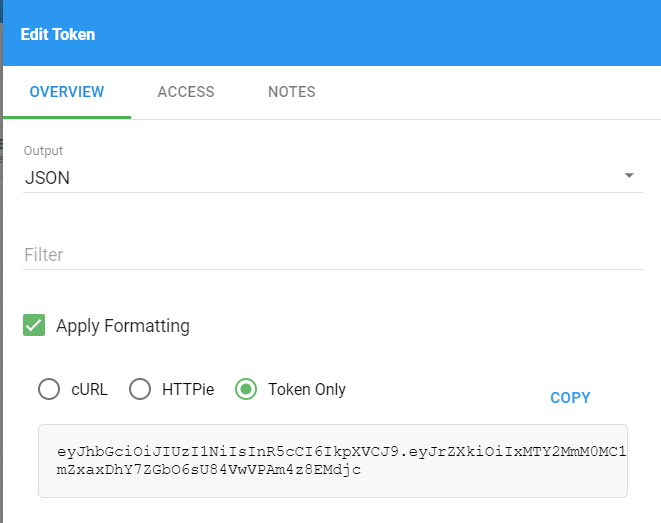
Now, you can use the above token as a Query Parameter:
/api/datasets/{id}/data?token=eyJhb....djc
Basic Authentication
Basic Authentication takes the credentials constructed by first combining the username and the password with a colon (aladdin:opensesame), and then encodes the resulting string in base64 (YWxhZGRpbjpvcGVuc2VzYW1l).
This base64 version of the username and password can then be sent along with your API Request via the headers:
Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
The implementation of this type of auth will differ depending on the how you are sending your API Requests.
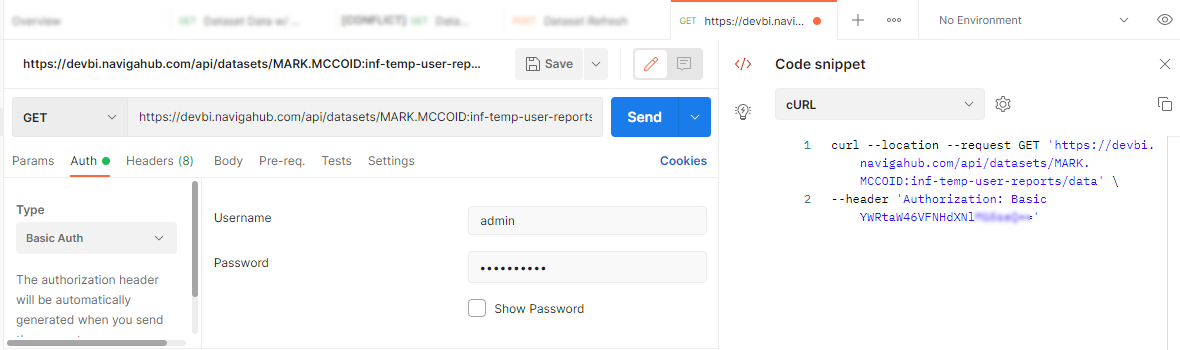
If you are testing out Route via the Postman app, then most of it is built in for you as you can see below. You will simply enter the username and password and Postman will take care of the rest. If you observe the code snippet to the right, you will see the Authorization header with the base64 encoded username and password.
Dataset Routes
GET - Request Data
The route that is used to get data from a dataset. Replace the {id} with the id of the Dataset.
/api/datasets/{id}/data
There are two options when getting the {id} for the dataset. You can either get a unique UUID or you can get the user:name-of-dataset.
The UUID is the best for stability, as renaming the Dataset will not affect this id.
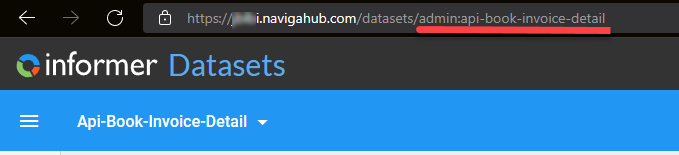
The easiest way to get the correct text id for the dataset is to open the dataset in Informer and copy the id from the browser URL bar. Below, you would copy admin:api-book-invoice-detail as the id:
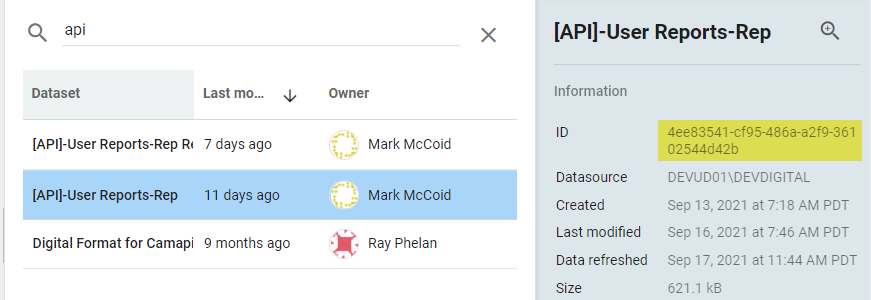
To get the UUID you will simply go to the Datasets area where you get a list of all of your dataset and select the dataset you want the UUID for. It will be listed in the right sidebar and will be called "ID":
Useful Parameters
You have some optional parameters that you can include via the query string, most useful are:
?start=0&limit=50&sort=_doc
These options will allow you to tell the API what data you want to retrieve from the dataset. This is very useful if you need to limit the amount of data coming back.
It also facilitates paging through the data. The sort parameter can be any field, but the most performat way to run it is by using the _doc field, which is an Elasticsearch field (you won't find it in your results).
NOTE: According to Entrinsik, if you don't need to sort by any specific field, then you should always include the sort by _doc option:
sort=_doc
Filtering the Dataset
There are two other optional parameters that you can use if you want to filter the data coming back.
- q - allows for simple filter on a single field - q Parameter Details & Examples
- filter - allows for more complicated filtering using the ElasticSearch Query DSL. filter Parameter Details & Examples
API Results JSON
{
"_links": {
"self": {
"href": "https://devbi.navigahub.com/api/datasets/MARK.MCCOID%3Ainf-temp-user-reports/data?start=0&limit=50"
},
"next": {
"href": "https://devbi.navigahub.com/api/datasets/MARK.MCCOID%3Ainf-temp-user-reports/data?start=50&limit=50"
}
},
"items": [
{
"LineNetAmount": 3000,
"RevenueDate": "2021-10-01T07:00:00.000Z",
"a_d_internet_gl_types_assoc_desc": "Print Display",
"advName": "Flying Toasters",
},
{
"LineNetAmount": 2304,
"RevenueDate": "2021-08-01T07:00:00.000Z",
"a_d_internet_gl_types_assoc_desc": "Print Display",
"advName": "FAY DRIVE BREWERY",
},
...
],
"start": 0,
"count": 50,
"total": 1898
}
The data will be in the items key and presented as an array of objects.
If you are paging through the data, then you will want to take note of the _links key. It will have a next key that contains the next start/limit options set up for you. It will also have a _prev key if needed and when you hit the end of the dataset data, the _next key will no longer be available.
The _prev and _next links take into account the initial limit value that you sent. For example, if you sent ?start=0&limit=100, the _next link would have the following query params ?start=100&limit=100
If you are using the next or prev, you can add the &sort=_doc.
GET - Exporters JSON/CSV/ETC
This is a great route if you don't need to page through the data and you just need all of the records.
/api/datasets/{id}/export/{exporter}
The most common exporters are json and csv. If you want to see the other options, you can call this endpoint (GET):
/api/datasets/exporters
There are a few other parameters that are optional.
-
omit - If you do not want certain fields to be included in the output, add an omit paramter for each field to omit:
/datasets/{id}/export/json?omit=productId&omit=productNameIf you have multiples, you can also send an Array of Strings through via one omit parameters
/datasets/{id}/export/json?omit=["webSiteId", "statusCode"]NOTE: The field names are the field aliases in your Informer Dataset, not the field label
-
include - If you only want certain fields to be included in the result, add them here. Note that you should not use both omit and include, choose one and use it if needed.
-
sort - sort by fields indicated. As with
omitandincludeif you need to sort by multiple fields, then add multiple sort paramters:/datasets/{id}/export/json?sort=productId&sort=productName -
q - allows for simple filter on a single field - q Parameter Details & Examples
-
filter - allows for more complicated filtering using the ElasticSearch Query DSL. filter Parameter Details & Examples
POST - Refresh Dataset
To programatically refresh a data use the following Route:
/api/datasets/{id}/_refresh
If you have Input values that you want to pass for the refresh, you can pass them in the body of the post as a JSON object:
{
params: {
nameOfInput: ["value", ...]
otherInput: [...]
}
}
Note: The type of input that you defined in the Dataset itself doesn't matter. For example, if you had defined an input as "Only allow a single value", you could still pass multiple values through the body and the refresh would use those values. The input dialogs you build on the dataset ONLY control what gets sent to this api. They are only a UX on top of this API. THey will not limit what you send.
Example of a raw JSON body sending a date and a campaign ID to the refresh:
{
"params": {
"startDate": ["09/01/2021"],
"campaignId": [6736, 6796]
}
}
PUT - Change Input Values
PUT /api/datasets/{id}
If you want to modify the Input value of a Dataset before it is run via a Job, you will use this PUT route with the following JSON Body.
{
"params": {
"inputAlias": ...value...
}
}
NOTE: You will only see this change in Jobs that are going to refresh the Dataset. If you open the dataset directly and got to "Change Inputs", you will see the default input value.
GET - Request Params
/api/datasets/{id}/params
This will return the last used set of params (input fields) for this dataset. In the example result below, you will see that it had an input field startDate that was used:
{
"_links": {
"self": {
"href": "https://devbi.navigahub.com/api/datasets/MARK.MCCOID%3Aapi-user-reports-rep/params"
}
},
"startDate": ["MONTH_BEGIN-1M"]
}
NOTE: The returned params list does NOT include all input values, ONLY the ones that were used on the last refresh of the Dataset.
GET - Dataset Info
The mother of the dataset requests will return all metadata information about a Dataset.
/api/datasets/{id}
You will have to play around with the returned JSON to find what you need, but one of interest will be the \_embedded.inf:query.settings.inputs which will give you a list of all available inputs, versus the Params, which will only give you inputs that were used on the last refresh.
{
"_links": {},
...
"_embedded": {
"inf:field": [],
"inf:query": {
"_links": {},
"naturalId": "694c8c1f-dec1-47fc-83eb-8c7c8eff6e0c",
"permissions": {
"assignTags": true,
"changeOwner": true,
"copy": true,
"delete": true,
"edit": true,
"rename": true,
"revisions": true,
"run": true,
"share": true,
"write": true
},
"id": "694c8c1f-dec1-47fc-83eb-8c7c8eff6e0c",
"tenant": "manager",
"ownerId": "MARK.MCCOID",
"slug": null,
"name": null,
"description": null,
"shared": false,
"embedded": true,
"source": null,
"sourceId": null,
"settings": {
"grid": {},
"chips": [],
"filter": {},
"useFakeData": false
},
"inputs": {
"multiInput": {
"inputs": [
{
"name": "startDate",
"type": "Input box",
"label": "startDate",
"component": {
"mdMultiInput": {
"type": "text",
"wildcard": false,
"delimiter": "comma",
"onlySingle": false,
"defaultValue": [
"MONTH_BEGIN-1M"
]
}
}
},
{
"name": "campaignId",
"type": "Input box",
"label": "IN Campaign ID",
"component": {
"mdMultiInput": {
"type": "text",
"wildcard": false,
"delimiter": "comma",
"onlySingle": true
}
}
}
],
"instructions": ""
}
},
"language": "informer",
"flow": [
{
"script": {}
},
{
"removeField": {
"fields": [
"netCost"
]
}
}
],
"payload": {},
"defnUpdatedAt": "2021-09-16T14:46:21.889Z",
"fields": {},
"limit": -1,
"createdAt": "2021-09-13T14:18:49.174Z",
"updatedAt": "2021-09-16T14:46:21.890Z",
"datasourceId": "538e966c-cbb9-42c6-830a-b228a91dbaaf",
"editingId": null,
"folderId": null,
...
},
"inf:datasource": {},
"inf:filter": []
}
}
GET - Index Count (Number of Rows in Dataset)
This route will return an integer with the count of rows in the dataset index.
/api/datasets/{id}/index/count
DELETE - Remove Data from a Dataset
This route will remove ALL data from a Dataset. Be careful with this one because if you mistype anything after the {id}/, the dataset may be deleted. Always have a Bundled backup of the dataset before testing.
/api/datasets/{id}/data?removeFields=false
Ad Hoc Query Report Routes
POST - Execute Report
This route will execute the report and return the data. Many reports have required or optional parameters and these can be sent in the body of the Post request.
The base route is:
/api/queries/{id}/_execute
Sending Input Values
If you have Input values that you want to pass to the report, you can pass them in the body of the post as a JSON object:
{
"invoiceId": ["1014956.1"]
}
Optional Parameters
You can attach some parameters to the request.
-
output - json | csv - default = JSON - This determines the output format. If left off, JSON will be returned. /api/queries/{id}/_execute?output=csv
For exporters like Excel, see the
_runcommand in the next section. -
limit - integer - default = -1 - This will limit the number of rows returned from the base query. The default of -1 will return ALL rows. This is the Row Limit found in the query editor.
-
pretty - true | false - Default = false - Should the results be formatted. Usually best to be left off or false.
-
applyformatting - true | false - Default = true - Apply the configured type formatting options from the grid. When checked, certain number options can cause numbers to appear as strings. When unchecked, dates will be strings in ISO-8601 standard format (eg. 2014-05-17T17:00:00.000Z).
**Results **
The results from this request will be JSON (array of objects):
[
{
"campaignId": "10863",
"id": "28259",
"webSiteId": "DEMO10",
...
},
{...},
...
POST - _run Report Command
The Dataset API offers the Exports route, but an Ad Hoc Query report accessed via the API, does not have this functionality directly.
You can get this functionality by use the /api/queries/{id}/_run route along with a few other steps.
The _run route does not return the data from the Ad Hoc Query report, but instead "runs" it and stores the data in a temporary Dataset in the background.
It also has a different format for sending input values to the report.
{
"params": {
"inputValue": ["2022-09"]
}
}
NOTE: Even if you have no input values, you must have an empty object in your post body -> {}
Next, find the following route in the Response of that call: _links -> inf:dataset -> href. The value here should be something like http://yourserveraddress.com/api/queries/{id}/dataset.
Issue a GET request against that URL.
Next, find the following route in the Response of that call: _links -> self -> href. The value here should be something like http://yourserveraddress.com/api/datasets/{id}.
This is the the route of the temporary Dataset behind the Ad hoc results, and you should can now use the Dataset Exporter Route to build a call to export the data the way you would export any other Dataset.
Cancel Dataset Refresh
If you need to cancel a Dataset Refresh that you initiate via the Dataset Refresh API call, you can do so via the monitors API route.
To be able to use the monitors route, you will need to modify how you call the Dataset Refresh via the API.
In the POST /api/datasets/{id}/_refresh you will need to add the following JSON Body
{
"progress": "...some unique identifier..."
}
You can then use this progress identified in the following monitors route. The {id} is the progress identifier that you added in the Dataset Refresh API call.
POST /api/monitors/{id}/_cancel
Live Excel
Live Excel uses a special POST query to get the data into Excel. This query, when pointed to an Ad Hoc Query, first runs the query and the sends the data formatted specifically for Excel. For Datasets, it does the same except it does NOT refresh the dataset.
If you open an iqy file in Notepad, you will see the query. We will look at the raw query and also how to format it to run in a curl statement.
Ad Hoc Report Live Excel Raw Query
https://baybi.navigahub.com/api/live-excel/token?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJrZXkiOiI5Njk1NGM5Yi1jMDY5LTQwOGMtYjU1Zi1kNjFhYjZlYjFhMDUiLCJpYXQiOjE2ODYyNTYzNDMuNDk4fQ.ivCggj_YEkohufd7o1o8JhHiXrNA9n5xXdGwHSvsNJU
query=99d6424a-c732-4109-ac7e-05bcb2f7c502&delimiter=,&mvHandling=customDelimit&showColumnHeaders=true
Converted to a Curl Statement
curl -X POST "https://baybi.navigahub.com/api/live-excel/token?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJrZXkiOiI5Njk1NGM5Yi1jMDY5LTQwOGMtYjU1Zi1kNjFhYjZlYjFhMDUiLCJpYXQiOjE2ODYyNTYzNDMuNDk4fQ.ivCggj_YEkohufd7o1o8JhHiXrNA9n5xXdGwHSvsNJU" -d "query=99d6424a-c732-4109-ac7e-05bcb2f7c502&delimiter=,&mvHandling=customDelimit&showColumnHeaders=true"
Dataset Live Excel Raw Query
https://baybi.navigahub.com/api/live-excel/token?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJrZXkiOiI1ZmVjNmJiYi0yM2Q5LTRlNGMtYTE3NC03YTE0ZDRjNGFhZDkiLCJpYXQiOjE2ODYyNTc2MjMuMzIzfQ.ozraeFIh6IeLia4sC8-SoPRd4hU5nLYoVx80AAsnRDk
dataset=e0e99154-ff65-404f-ab1c-44c1ef6b0d75&delimiter=,&mvHandling=customDelimit&showColumnHeaders=true
Converted to a Curl Statment
curl -X POST "https://baybi.navigahub.com/api/live-excel/token?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJrZXkiOiI1ZmVjNmJiYi0yM2Q5LTRlNGMtYTE3NC03YTE0ZDRjNGFhZDkiLCJpYXQiOjE2ODYyNTc2MjMuMzIzfQ.ozraeFIh6IeLia4sC8-SoPRd4hU5nLYoVx80AAsnRDk" -d "dataset=e0e99154-ff65-404f-ab1c-44c1ef6b0d75&delimiter=,&mvHandling=customDelimit&showColumnHeaders=true"
If you have an issue with CURL in Powershell, it may be aliased as something else. Just run the following in your Powershell
$ remove-item alias:curl
Saved Functions
The average user will never need these routes, I have added them here in case anyone is interested.
GET - Saved Functions List
/api/functions
This route will take either a token or Basic Auth and will return a list of Saved Function found in the Administration area.
The output format will be an array of the follow objects:
{
"id": "a48b6a10-5323-4cbf-ad33-f8e9a52fc46b",
"name": "calculateLineAmounts",
"namespace": "naviga",
"description": "Calculate Line foreign, local, gross and net amounts",
"script": " const { actAmount, estAmount, \n campaignType, exchangeRate = 1, \n agencyCommMethod = 1, \n return returnANumber(grossAmt * agencyCommissionPct);\n}\n\n",
"params": [
{
"id": "inputObj",
"label": "inputObj",
"sample": "",
"dataType": "any"
}
],
"createdAt": "2023-02-27T19:24:25.359Z",
"updatedAt": "2023-03-21T15:02:05.624Z"
}
POST - Create a Saved Function
/api/functions
This is the same route, but will contain a body of JSON data that defines the function
Before creating a new function, it is good practice to get a list of existing functions using the GET verb and if the name you are trying to create exists in the same Namespace, then don't create it. I would go as far to say, if the name exists in ANY namespace, don't create it.
It looks like the POST call itself does some checking on uniqueness of the name within the namespace.
The body of this route contains all the data for the new function. Here is the format:
{
"name": "nameOfFunction",
"namespace": "Namespace",
"description": "Description of Function",
"script": "Stringified code. Make sure to run the code through JSON.stringify()",
"params": [
{
"id": "inputObj",
"label": "inputObj",
"sample": "",
"dataType": "any"
}
]
}
Also, be aware that if you script code has any errors, it will not be created, but your response will be:
{
"statusCode": 400,
"error": "Bad Request",
"message": "Function invalid: xbox is not defined"
}
Other Information
q examples
You can filter on a single field using the q parameter. If you need multiple values, separate them by a space
q=campaignId:6736
OR
q=repName="Rep Name"
Here is an example:
...&q=repName:"Tina Turner" "Dwayne Johnson"
filter examples
The filter param must be a valid JSON string. The filter is actually an query built using the ElasticSearch Query DSL.
These filters are a good way to extract certain data from a dataset instead of pulling all the data.
The Query DSL is complicated in its own right, so I will just give you a few simple examples, but do explore the documentation above for more details.
Below you will find the DSL that I was able to test. The match keyword is supposed to be a fuzzy match, but I have found that it does not work and so I am only using the terms keyword, which gives us exact matching.
Terms Keyword - Exact Match
The terms keyword expects the matching value(s) to be an array, hence, enclosed is square brackets [].
Even if you have only one value to check, if you are using the terms keyword, you must enclose in []. If you have only one, you can instead use the term keyword.
I find it more clear to simply always use terms and [] around my search value.
// Match Single
{ "terms": { "campaignId": [11677]}}
// Match multiple
{ "terms": { "campaignId": [11677,11712]}}
Date Range Filter
You can send a date range Elasticsearch filter using the range keyword with the gte and lte modifiers.
{
"range": {
"a_d_internet_campaigns_assoc_dateEntered": {
"gte":"2023-01-01",
"lte": "2023-03-01"
}
}
}
// Without formatting
{"range":{"a_d_internet_campaigns_assoc_dateEntered":{"gte":"2023-01-01","lte": "2023-03-01"}}}
Compound Filters
If you need to filter data on multiple fields, you will put them in a filter block. This will perform an and operation between each of the filter operations.
{
"bool": {
"filter": [
{"range":{"a_d_internet_campaigns_assoc_dateEntered":{"gte":"2023-01-01","lte": "2023-03-01"}}},
{"terms": { "webSiteId": ["DEMO11"]}},
{"terms": { "a_d_internet_campaigns_assoc_advName": ["FAY DRIVE BREWERY"]}}
]
}
}
// Without formatting
{"bool":{"filter":[{"range":{"a_d_internet_campaigns_assoc_dateEntered":{"gte":"2023-01-01","lte":"2023-03-01"}}},{"terms":{"webSiteId":["DEMO11"]}},{"terms":{"a_d_internet_campaigns_assoc_advName":["FAY DRIVE BREWERY"]}}]}}
Common Exporters
These exporters should work with all datasets, however, you can use the following API request to verify for your specific Dataset.
/api/datasets/exporters
[
{
"id": "csv",
"editor": "csvEdit",
"download": true,
"extension": "csv",
"contentType": "text/csv",
"canApplyFilter": true,
"canUseInJob": true,
"canToggleFormatting": true,
"applyFormatting": true
},
{
"id": "html",
"editor": "htmlEdit",
"contentType": "text/html",
"extension": "html",
"download": true,
"canApplyFilter": true,
"canUseInJob": true,
"canToggleFormatting": true,
"applyFormatting": true
},
{
"id": "x-ms-iqy",
"editor": "iqyEdit",
"contentType": "text/x-ms-iqy",
"extension": "iqy",
"canApplyFilter": false,
"canUseInJob": false,
"canToggleFormatting": false,
"applyFormatting": true,
"download": true
},
{
"id": "json",
"applyFormatting": false,
"editor": "jsonEdit",
"download": true,
"extension": "json",
"contentType": "application/json",
"canApplyFilter": true,
"canUseInJob": true,
"canToggleFormatting": true
},
{
"id": "xlsx",
"contentType": "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
"extension": "xlsx",
"editor": "xlsxEdit",
"canToggleFormatting": false,
"applyFormatting": true,
"download": true,
"canApplyFilter": true,
"canUseInJob": true
},
{
"id": "xml",
"editor": "xmlEdit",
"download": true,
"extension": "xml",
"contentType": "application/xml",
"canApplyFilter": true,
"canUseInJob": true,
"canToggleFormatting": true,
"applyFormatting": true
},
{
"id": "saved-list",
"editor": "savedListEdit",
"contentType": "text/u2",
"canToggleFormatting": false,
"download": false,
"extension": false,
"canApplyFilter": true,
"canUseInJob": true,
"applyFormatting": true
},
{
"id": "tabDelimited",
"contentType": "text/tab-separated-values",
"extension": "txt",
"editor": "tabDelimitedEdit",
"download": true,
"canApplyFilter": true,
"canUseInJob": true,
"canToggleFormatting": true,
"applyFormatting": true
},
{
"id": "customDelimited",
"contentType": "text/custom-delimited-values",
"extension": "txt",
"editor": "customDelimitedEdit",
"download": true,
"canApplyFilter": true,
"canUseInJob": true,
"canToggleFormatting": true,
"applyFormatting": true
},
{
"id": "fixedLength",
"contentType": "text/plain+fixed",
"extension": "txt",
"editor": "fixedLengthEdit",
"download": true,
"canApplyFilter": true,
"canUseInJob": true,
"canToggleFormatting": true,
"applyFormatting": true
},
{
"id": "pdf",
"contentType": "application/pdf",
"editor": "pdfEdit",
"extension": "pdf",
"download": true,
"canApplyFilter": true,
"canUseInJob": true,
"canToggleFormatting": true,
"applyFormatting": true
}
]
Uses
Google Sheets Live Import
There is an option to export to a Live Excel file format in Informer, but this will not work if you are using Google Sheets.
To get a similar experience in Google Sheets, you will need to couple the JSON Exporter with a special add on function in Google Sheets that will import and covert your JSON to spreadsheet cells.
The "how-to" is documented here: https://apipheny.io/import-json-google-sheets/
If you know how to use Apps Scripts, the full script is show at the end of this section. It is suggested to rename it to ImportJSON
Once you have the script setup, you will need to generate/create an API call that exports JSON for the Dataset you are using.
Since you are reading the docs, you can manually do this by following the instructions for GET - Exporters JSON/CSV/ETC.
OR, you can click on the actions menu and choose Create a Data Access Token. This will bring up the following screen, where you will only need the HTTPS://... API url.
You will need to generate a token even if you manually create the API link. This token will authenticate your request.

ImportJSON script
/**
* Retrieves all the rows in the active spreadsheet that contain data and logs the
* values for each row.
* For more information on using the Spreadsheet API, see
* https://developers.google.com/apps-script/service_spreadsheet
*/
function readRows() {
var sheet = SpreadsheetApp.getActiveSheet();
var rows = sheet.getDataRange();
var numRows = rows.getNumRows();
var values = rows.getValues();
for (var i = 0; i <= numRows - 1; i++) {
var row = values[i];
Logger.log(row);
}
};
/**
* Adds a custom menu to the active spreadsheet, containing a single menu item
* for invoking the readRows() function specified above.
* The onOpen() function, when defined, is automatically invoked whenever the
* spreadsheet is opened.
* For more information on using the Spreadsheet API, see
* https://developers.google.com/apps-script/service_spreadsheet
*/
function onOpen() {
var sheet = SpreadsheetApp.getActiveSpreadsheet();
var entries = [{
name : "Read Data",
functionName : "readRows"
}];
sheet.addMenu("Script Center Menu", entries);
};
/*====================================================================================================================================*
ImportJSON by Trevor Lohrbeer (@FastFedora)
====================================================================================================================================
Version: 1.1
Project Page: http://blog.fastfedora.com/projects/import-json
Copyright: (c) 2012 by Trevor Lohrbeer
License: GNU General Public License, version 3 (GPL-3.0)
http://www.opensource.org/licenses/gpl-3.0.html
------------------------------------------------------------------------------------------------------------------------------------
A library for importing JSON feeds into Google spreadsheets. Functions include:
ImportJSON For use by end users to import a JSON feed from a URL
ImportJSONAdvanced For use by script developers to easily extend the functionality of this library
Future enhancements may include:
- Support for a real XPath like syntax similar to ImportXML for the query parameter
- Support for OAuth authenticated APIs
Or feel free to write these and add on to the library yourself!
------------------------------------------------------------------------------------------------------------------------------------
Changelog:
1.1 Added support for the noHeaders option
1.0 Initial release
*====================================================================================================================================*/
/**
* Imports a JSON feed and returns the results to be inserted into a Google Spreadsheet. The JSON feed is flattened to create
* a two-dimensional array. The first row contains the headers, with each column header indicating the path to that data in
* the JSON feed. The remaining rows contain the data.
*
* By default, data gets transformed so it looks more like a normal data import. Specifically:
*
* - Data from parent JSON elements gets inherited to their child elements, so rows representing child elements contain the values
* of the rows representing their parent elements.
* - Values longer than 256 characters get truncated.
* - Headers have slashes converted to spaces, common prefixes removed and the resulting text converted to title case.
*
* To change this behavior, pass in one of these values in the options parameter:
*
* noInherit: Don't inherit values from parent elements
* noTruncate: Don't truncate values
* rawHeaders: Don't prettify headers
* noHeaders: Don't include headers, only the data
* debugLocation: Prepend each value with the row & column it belongs in
*
* For example:
*
* =ImportJSON("http://gdata.youtube.com/feeds/api/standardfeeds/most_popular?v=2&alt=json", "/feed/entry/title,/feed/entry/content",
* "noInherit,noTruncate,rawHeaders")
*
* @param {url} the URL to a public JSON feed
* @param {query} a comma-separated lists of paths to import. Any path starting with one of these paths gets imported.
* @param {options} a comma-separated list of options that alter processing of the data
*
* @return a two-dimensional array containing the data, with the first row containing headers
* @customfunction
**/
function ImportJSON(url, query, options) {
return ImportJSONAdvanced(url, query, options, includeXPath_, defaultTransform_);
}
/**
* An advanced version of ImportJSON designed to be easily extended by a script. This version cannot be called from within a
* spreadsheet.
*
* Imports a JSON feed and returns the results to be inserted into a Google Spreadsheet. The JSON feed is flattened to create
* a two-dimensional array. The first row contains the headers, with each column header indicating the path to that data in
* the JSON feed. The remaining rows contain the data.
*
* Use the include and transformation functions to determine what to include in the import and how to transform the data after it is
* imported.
*
* For example:
*
* =ImportJSON("http://gdata.youtube.com/feeds/api/standardfeeds/most_popular?v=2&alt=json",
* "/feed/entry",
* function (query, path) { return path.indexOf(query) == 0; },
* function (data, row, column) { data[row][column] = data[row][column].toString().substr(0, 100); } )
*
* In this example, the import function checks to see if the path to the data being imported starts with the query. The transform
* function takes the data and truncates it. For more robust versions of these functions, see the internal code of this library.
*
* @param {url} the URL to a public JSON feed
* @param {query} the query passed to the include function
* @param {options} a comma-separated list of options that may alter processing of the data
* @param {includeFunc} a function with the signature func(query, path, options) that returns true if the data element at the given path
* should be included or false otherwise.
* @param {transformFunc} a function with the signature func(data, row, column, options) where data is a 2-dimensional array of the data
* and row & column are the current row and column being processed. Any return value is ignored. Note that row 0
* contains the headers for the data, so test for row==0 to process headers only.
*
* @return a two-dimensional array containing the data, with the first row containing headers
**/
function ImportJSONAdvanced(url, query, options, includeFunc, transformFunc) {
var jsondata = UrlFetchApp.fetch(url);
var object = JSON.parse(jsondata.getContentText());
return parseJSONObject_(object, query, options, includeFunc, transformFunc);
}
/**
* Encodes the given value to use within a URL.
*
* @param {value} the value to be encoded
*
* @return the value encoded using URL percent-encoding
*/
function URLEncode(value) {
return encodeURIComponent(value.toString());
}
/**
* Parses a JSON object and returns a two-dimensional array containing the data of that object.
*/
function parseJSONObject_(object, query, options, includeFunc, transformFunc) {
var headers = new Array();
var data = new Array();
if (query && !Array.isArray(query) && query.toString().indexOf(",") != -1) {
query = query.toString().split(",");
}
if (options) {
options = options.toString().split(",");
}
parseData_(headers, data, "", 1, object, query, options, includeFunc);
parseHeaders_(headers, data);
transformData_(data, options, transformFunc);
return hasOption_(options, "noHeaders") ? (data.length > 1 ? data.slice(1) : new Array()) : data;
}
/**
* Parses the data contained within the given value and inserts it into the data two-dimensional array starting at the rowIndex.
* If the data is to be inserted into a new column, a new header is added to the headers array. The value can be an object,
* array or scalar value.
*
* If the value is an object, it's properties are iterated through and passed back into this function with the name of each
* property extending the path. For instance, if the object contains the property "entry" and the path passed in was "/feed",
* this function is called with the value of the entry property and the path "/feed/entry".
*
* If the value is an array containing other arrays or objects, each element in the array is passed into this function with
* the rowIndex incremeneted for each element.
*
* If the value is an array containing only scalar values, those values are joined together and inserted into the data array as
* a single value.
*
* If the value is a scalar, the value is inserted directly into the data array.
*/
function parseData_(headers, data, path, rowIndex, value, query, options, includeFunc) {
var dataInserted = false;
if (isObject_(value)) {
for (key in value) {
if (parseData_(headers, data, path + "/" + key, rowIndex, value[key], query, options, includeFunc)) {
dataInserted = true;
}
}
} else if (Array.isArray(value) && isObjectArray_(value)) {
for (var i = 0; i < value.length; i++) {
if (parseData_(headers, data, path, rowIndex, value[i], query, options, includeFunc)) {
dataInserted = true;
rowIndex++;
}
}
} else if (!includeFunc || includeFunc(query, path, options)) {
// Handle arrays containing only scalar values
if (Array.isArray(value)) {
value = value.join();
}
// Insert new row if one doesn't already exist
if (!data[rowIndex]) {
data[rowIndex] = new Array();
}
// Add a new header if one doesn't exist
if (!headers[path] && headers[path] != 0) {
headers[path] = Object.keys(headers).length;
}
// Insert the data
data[rowIndex][headers[path]] = value;
dataInserted = true;
}
return dataInserted;
}
/**
* Parses the headers array and inserts it into the first row of the data array.
*/
function parseHeaders_(headers, data) {
data[0] = new Array();
for (key in headers) {
data[0][headers[key]] = key;
}
}
/**
* Applies the transform function for each element in the data array, going through each column of each row.
*/
function transformData_(data, options, transformFunc) {
for (var i = 0; i < data.length; i++) {
for (var j = 0; j < data[i].length; j++) {
transformFunc(data, i, j, options);
}
}
}
/**
* Returns true if the given test value is an object; false otherwise.
*/
function isObject_(test) {
return Object.prototype.toString.call(test) === '[object Object]';
}
/**
* Returns true if the given test value is an array containing at least one object; false otherwise.
*/
function isObjectArray_(test) {
for (var i = 0; i < test.length; i++) {
if (isObject_(test[i])) {
return true;
}
}
return false;
}
/**
* Returns true if the given query applies to the given path.
*/
function includeXPath_(query, path, options) {
if (!query) {
return true;
} else if (Array.isArray(query)) {
for (var i = 0; i < query.length; i++) {
if (applyXPathRule_(query[i], path, options)) {
return true;
}
}
} else {
return applyXPathRule_(query, path, options);
}
return false;
};
/**
* Returns true if the rule applies to the given path.
*/
function applyXPathRule_(rule, path, options) {
return path.indexOf(rule) == 0;
}
/**
* By default, this function transforms the value at the given row & column so it looks more like a normal data import. Specifically:
*
* - Data from parent JSON elements gets inherited to their child elements, so rows representing child elements contain the values
* of the rows representing their parent elements.
* - Values longer than 256 characters get truncated.
* - Values in row 0 (headers) have slashes converted to spaces, common prefixes removed and the resulting text converted to title
* case.
*
* To change this behavior, pass in one of these values in the options parameter:
*
* noInherit: Don't inherit values from parent elements
* noTruncate: Don't truncate values
* rawHeaders: Don't prettify headers
* debugLocation: Prepend each value with the row & column it belongs in
*/
function defaultTransform_(data, row, column, options) {
if (!data[row][column]) {
if (row < 2 || hasOption_(options, "noInherit")) {
data[row][column] = "";
} else {
data[row][column] = data[row-1][column];
}
}
if (!hasOption_(options, "rawHeaders") && row == 0) {
if (column == 0 && data[row].length > 1) {
removeCommonPrefixes_(data, row);
}
data[row][column] = toTitleCase_(data[row][column].toString().replace(/[\/\_]/g, " "));
}
if (!hasOption_(options, "noTruncate") && data[row][column]) {
data[row][column] = data[row][column].toString().substr(0, 256);
}
if (hasOption_(options, "debugLocation")) {
data[row][column] = "[" + row + "," + column + "]" + data[row][column];
}
}
/**
* If all the values in the given row share the same prefix, remove that prefix.
*/
function removeCommonPrefixes_(data, row) {
var matchIndex = data[row][0].length;
for (var i = 1; i < data[row].length; i++) {
matchIndex = findEqualityEndpoint_(data[row][i-1], data[row][i], matchIndex);
if (matchIndex == 0) {
return;
}
}
for (var i = 0; i < data[row].length; i++) {
data[row][i] = data[row][i].substring(matchIndex, data[row][i].length);
}
}
/**
* Locates the index where the two strings values stop being equal, stopping automatically at the stopAt index.
*/
function findEqualityEndpoint_(string1, string2, stopAt) {
if (!string1 || !string2) {
return -1;
}
var maxEndpoint = Math.min(stopAt, string1.length, string2.length);
for (var i = 0; i < maxEndpoint; i++) {
if (string1.charAt(i) != string2.charAt(i)) {
return i;
}
}
return maxEndpoint;
}
/**
* Converts the text to title case.
*/
function toTitleCase_(text) {
if (text == null) {
return null;
}
return text.replace(/\w\S*/g, function(word) { return word.charAt(0).toUpperCase() + word.substr(1).toLowerCase(); });
}
/**
* Returns true if the given set of options contains the given option.
*/
function hasOption_(options, option) {
return options && options.indexOf(option) >= 0;
}