Informer System Stuff
Clearing the Job Queue
If you find that you have Jobs that are in the queued state and/or Jobs that have been running for hours (or longer than they should). Your first line of defense will be clearing the existing queue and stopping any "hung" jobs.
Step 1
Open one browser tab showing your Jobs. Open another browser tab showing the Administration panel.
In the Administration panel, go to Settings and then scroll to the Jobs section and find the Enabled switch. Turn this switch OFF. It will be Gray instead of Green.
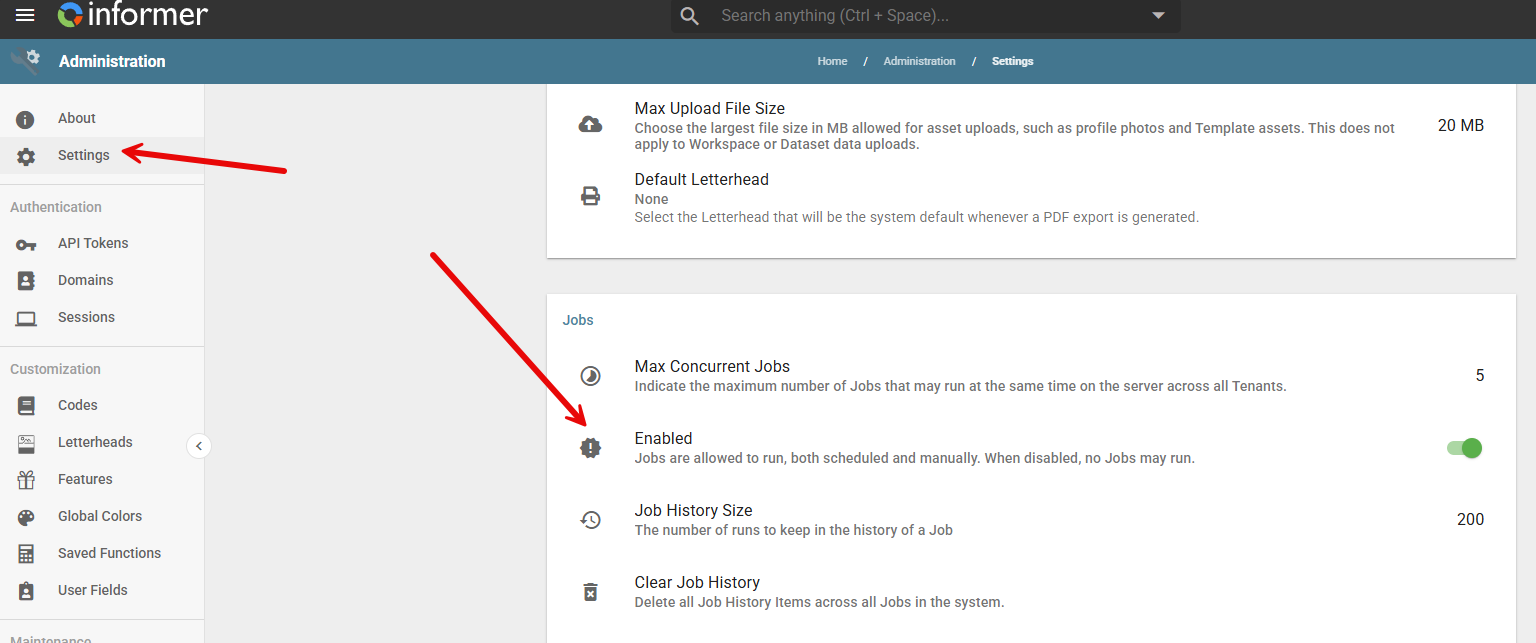
Step 2
Go to the browser tab that has the Jobs screen open. Find all jobs that are "hung", these jobs will have a running time shown in the Running Time column. Click on the Action menu by the Job and choose Stop. Do this for all hung jobs.
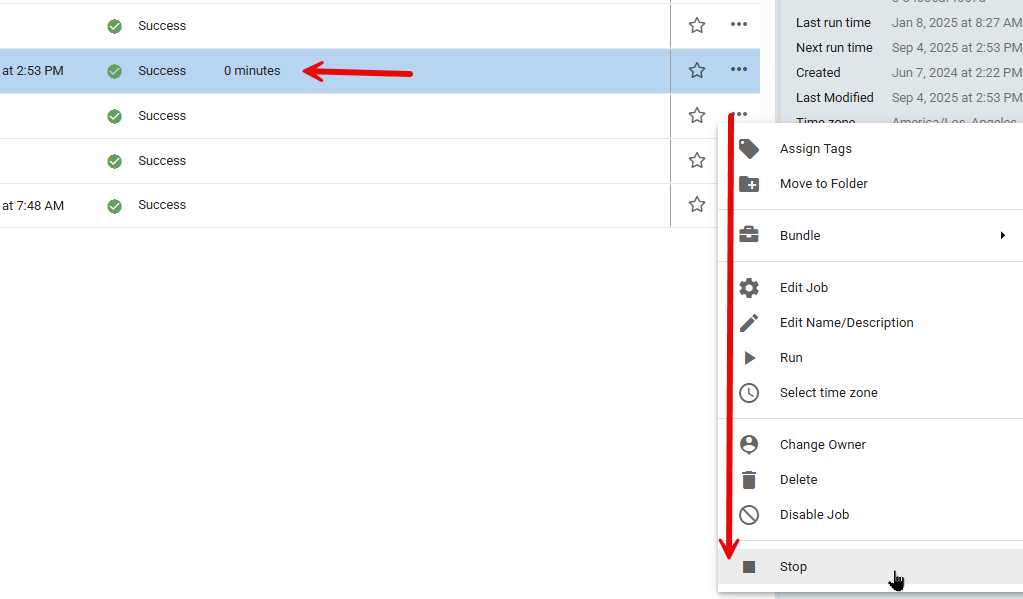
Step 3
Go back to the Administration tab and reenable the Jobs.
If you still experience issues, enter a Salesforce case as we may need to restart services on your Informer Server.
Setting Up Informer Metadata Database as Datasource v5.8.6 forward
The Informer Metadata database has details about all of the inner workings of your Informer system. Not only does it hold the Metadata for your system, it also holds the Audit logs if you have them turned on in the system settings.
If your Informer Metadata database is not yet created, you can create one by simply going to the New button, navigating to Datasource and then choosing Informer. To check if you have this datasource already, simply go to your Datasource area and look for a datasource with the type Informer. If it exists, you do not need to create one.
You will be asked to name the database. It can be anything, but I use Informer Metadata
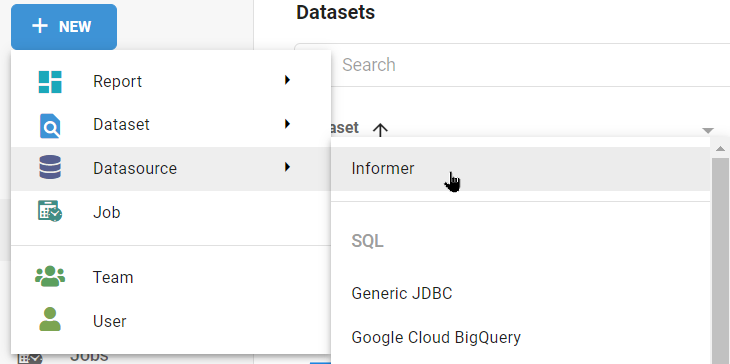
You are almost done. Now you need to scan the new datasource.
Navigate to Datasources -> InformerMetadata and click on the Mappings link in the Left Menu.
Then click on Scan Datasource and in the next dialog make sure to change to a Full Scan and then click on Scan


Download a Bundle of Sample Datasets using the Informer Metadata datasource.
Setting up Informer Postgres Database as Datasource (Only in v5.6.5 and Before)
This Datasource will provide you with metadata about the Reports, Datasets and Jobs that you have created within Informer.
One common use for this data is to track Jobs and if they are successful. You can setup a dataset (in a job) to run every day and send you an email when a job fails or hangs. Here is a sample
The information below is for Informer v5.1.2 to v5.6.5
Download the following TGZ file to your hard drive:
This file has all the information needed to create the Datasource, mappings, and sample Datasets.
Once downloaded, navigate to the Datasource page within Informer.
Simply drag and drop the downloaded tgz file onto this page:
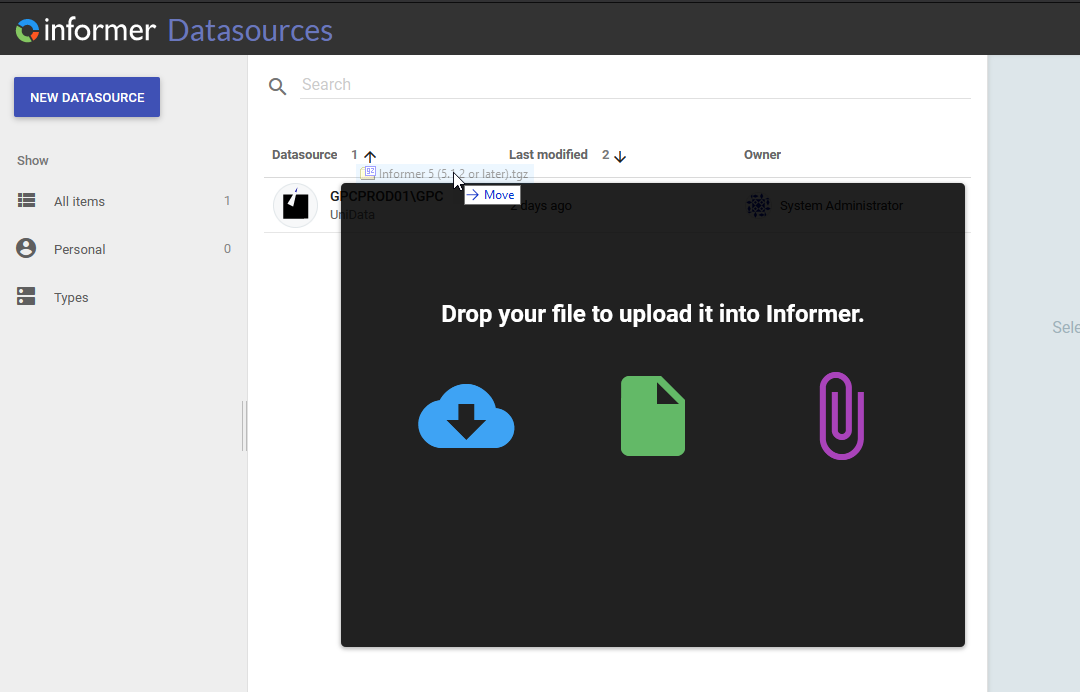
You will then be presented with a dialog where you can enter the new Datasource information.
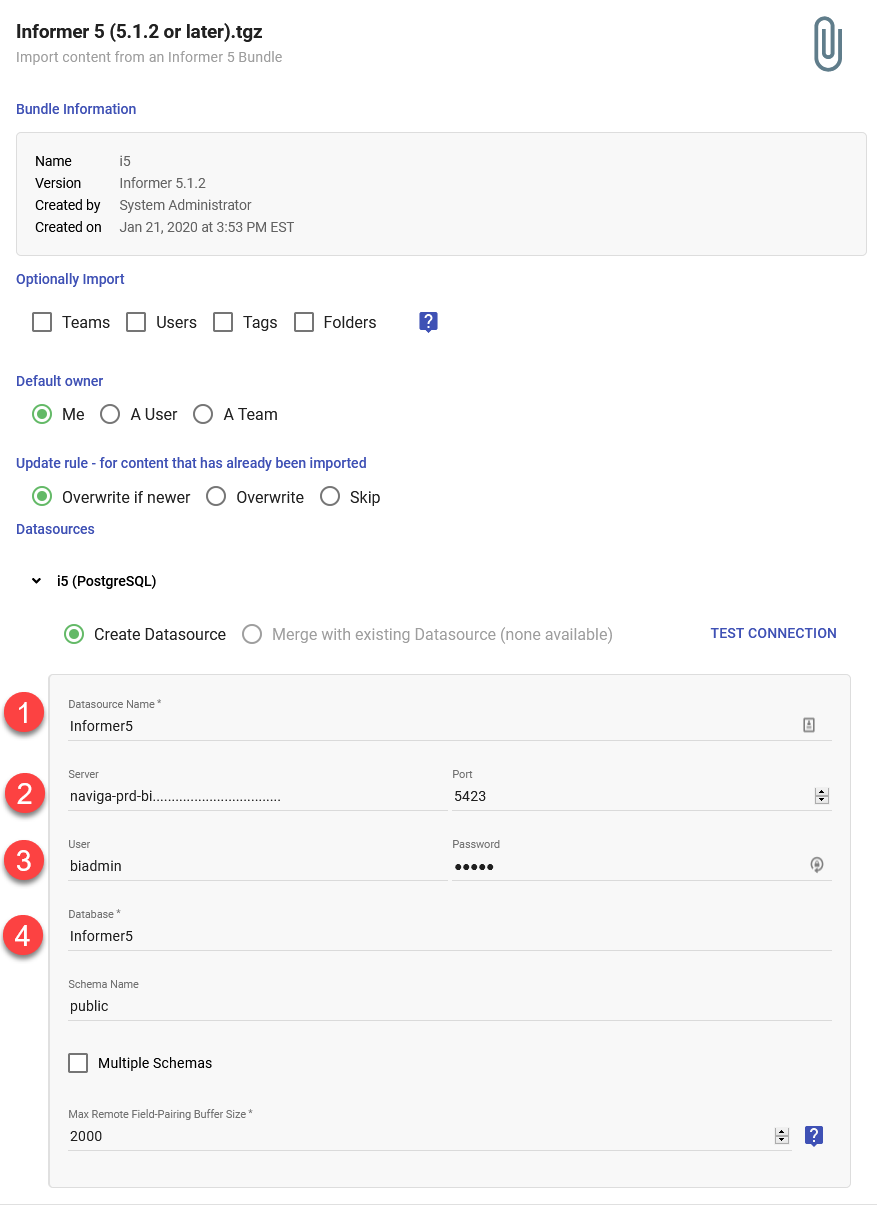
- Datasource Name - Can be anything, but Informer5 makes sense.
- Server and Port - You will need to get this information from whoever setup the Informer instance. There is a config.json file that will be on the server with this information, usually found in
C:\Entrinsik\Informer5 - User and Password - You will need to get this information from whoever setup the Informer instance.
- Database - Use the text you find in the Config File under the
databasekey.
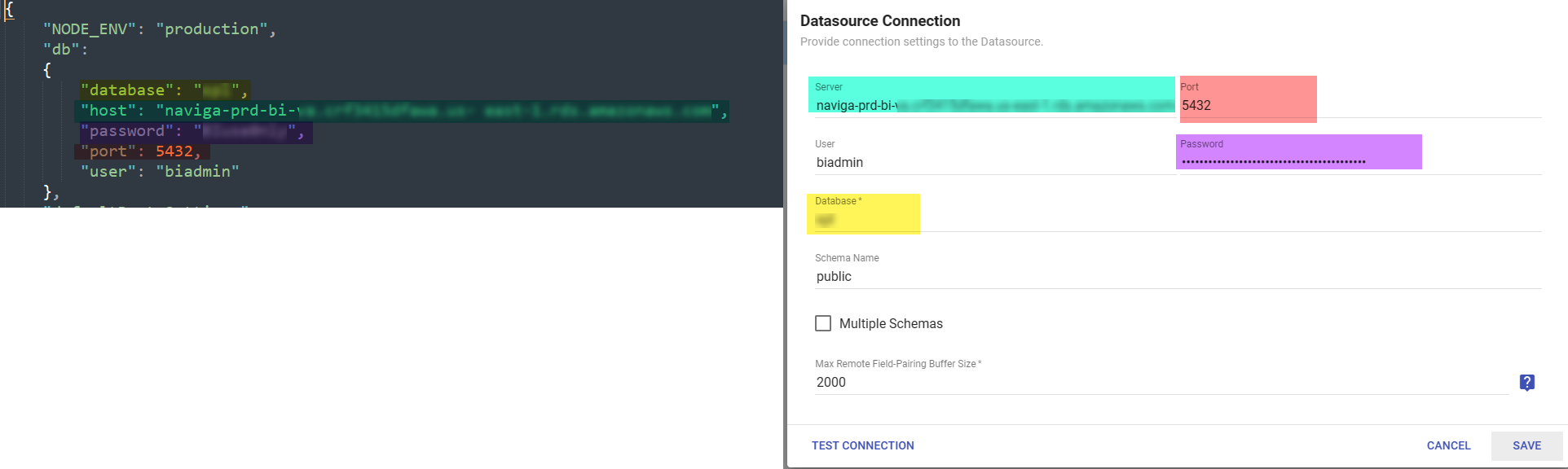
Then click Save and the Informer5 Datasource will be created along with all the mappings and nine sample Datasets.
To keep things organized, go to the Datasets page and find the nine Datasets just created, they will be found by looking for ones with the Datasource of "Informer5".
Create a new Folder called Informer_System and move these nine Datasets into it.
Job Status Dataset
This a Job Status sample Dataset, it is pretty easy to build your own, but here is a sample one.
Sample Job Status Dataset Bundle
A few things to note about how the relationship between these tables. The most useful relationship is between the Job and Job History mappings.

There should be one row for every job in the Job mapping which then links to the Job History mapping, which will have one row for EVERY time the job was run, hence the name history. Most of the fields in the Job mapping do not change over time. For example, the StartOn field is NOT when a job starts running, but is the date when the job was originally configured.
The Job History mapping gets a new row every time the Job runs, but it is updated at the "end" of the Job, whether it ends in success or failure. This means that it is difficult to find jobs that are hung and never finish.
The best way to do this is to look at the Job.LockedAt field. This field gets set to a date when the job starts running and indicates that it is locked, hence it shouldn't be changed (it is locked). The changes are held until the job finishes and then applied to the Job.
Since the Job History mapping has the data in it that we are looking for like the success flag, and we really only care about recent runs of the job, you will want to add criteria that filters your report by fields in the Job History mapping. Things like the following:
- Updated At - This was the last time that the job was Updated
- Success - Boolean - true or false.
NOTE: The above fields are updated when the job finishes running.
Here is a sample criteria that might be used:
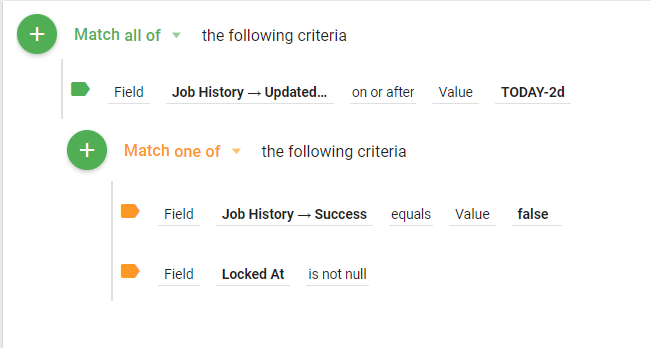
This criteria will pull any job that has a history with an updated date of the current date minus two days. This means that the job must have FINISHED in the last two days to be included. From those results, we then look for jobs that EITHER were NOT successful OR still have a LockedAt date. We are looking at the Locked At date because if it is not empty, then we can assume the Job is locked (or it is still running).
NOTE: If you have a Job that runs on a weekly basis, you may need to adjust the first criteria for the Updated Date.